· 24 min read
Microsoft To Do + Artificial Intelligence in To Do Vo Do

To Do Vo Do + OpenAI Api = Chatte mit deinen Aufgaben.
Zum Erforschen der neuen Generativen AI Errungenschaften wurde To Do Vo Do um ein experimentelles Feature erweitert. Man kann nun mit seinen Aufgaben aus Microsoft To Do “chatten”. To Do Vo Do verwendet nicht das Azure OpenAI Service sondern direkt das OpenAI Api. Man muss sich dazu einen Api Key auf OpenAI generieren lassen und diesen in To Do Vo Do einstellen. In diesem Artikel geht es nur kurz um die Vorstellung des neuen Features von To Do Vo Do. Wir beschäftigen uns, wie die Generative KI funktioniert, wie man sie für diesen speziellen Fall der Aufgabenverwaltung verwendet und welche Erkenntnisse daraus gewonnen wurden. Microsoft hat angekündigt, dass Daten vom Graph API in Zukunft über den [Microsoft 365 Copilot] (https://news.microsoft.com/de-de/wir-stellen-vor-microsoft-365-copilot/), bzw. Windows Copilot zur Verfügung gestellt werden, somit wird man auch darüber bald mit seine Aufgaben arbeiten können.
Dieser Artikel wurde ganz ohne künstlicher Intelligenz erstellt, so wie alle bisherigen Artikel dieses Blogs.
0. Motivation
Ich dachte nicht, dass die KI (Künstliche Intelligenz = AI = Artificial Intelligence) einen so großen Fortschritt macht. Seit ich DALL·E 2 von OpenAI gesehen habe, wurde mein Interesse aber geweckt und mit der Vorstellung von ChatGPT nochmals gesteigert. Seitdem habe ich mich, wie wohl sehr viele, damit gespielt und ich habe viele Videos angesehen. (Die meisten davon halten nicht, was der Titel oder das Thumbnail verspricht. “mindblowing, awesome, gamechanger, unlock the true potential, changes everything, …“) Vor allem hat mich interessiert, wie man seine eigenen Daten indizieren lassen kann, um damit zu arbeiten. Die Bing Erweiterung im Edge Browser bietet dazu einiges. Was angezeigt wird im Browser kann nun verarbeitet werden. Aber wie geht das und warum gibt es so große Einschränkungen, z.B. wenn das Dokument sehr groß ist? Ich habe eine Library gefunden (LangChain), welche die Anbindung an die LLMs (Large Language Models), wie es das OpenAI Api zur Verfügung stellt, sehr vereinfacht. Gleich vorweg, ich habe es geschafft, dass man mit all seinen Tasks und der KI arbeiten kann, aber eine wirklich sinnvolle Frage an den Chat ist mir noch nicht eingefallen. Der Weg, den Microsoft geht, die Anbindung aller persönlichen Daten aus dem Microsoft Graph (Dokumente, E-Mails, Kalender, …) an die KI, macht da sicher Sinn.
Auch zu diesem Blogeintrag gibt es YouTube Videos:
Verwendung des neuen Features: Microsoft To Do Tasks + Artificial Intelligence von OpenAI mit To Do Vo Do:

Dazu auch einen Hilfe Eintrag im To Do Vo Do Blog: Tasks + AI with To Do Vo Do.
Wie funktioniert das? Chatten mit Microsoft To Do - OpenAI Embeddings, Prompting, Vektor DB und GPT:

1. Wie kann man das ausprobieren?
Auf der Seite Settings (Menü/Settings) kann man den OpenAPI Key hinterlegen. Einen OpenAPI Key kann man sich auf der Seite OpenAI Apps erstellen, indem man oben rechts auf sein Profilbild klickt und im Menü dann View API keys auswählt.
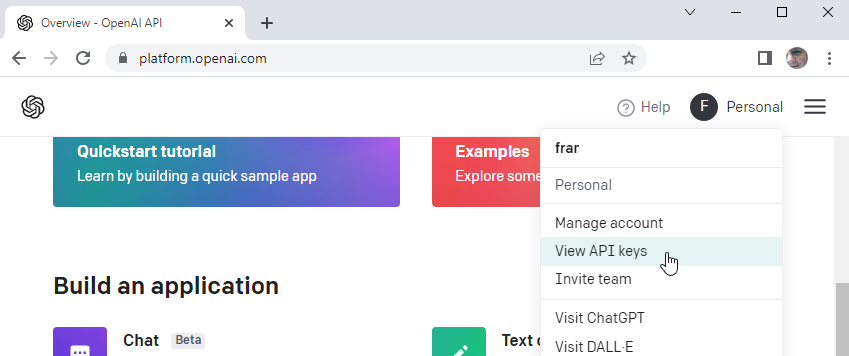
Mir ist bewusst, dass dies umständlich wirkt. Einfacher für den Benutzer wäre es, wenn die Anbindung serverseitig gemacht wird. Allerdings würden dann die Task Daten über meinen Server laufen und ich will eigentlich nicht, dass mir die Benutzer vertrauen müssen, dass ich die Daten nicht einsehe. Außerdem würden dann Kosten bei mir anfallen.
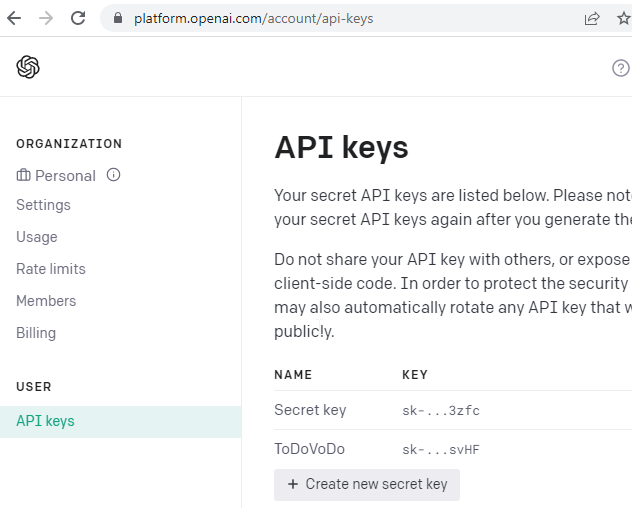
Um nun einen Key anzufordern, klickt man auf Create new secret key. Dazu muss man allerdings wissen, dass man nach einer Kreditkarte gefragt wird. Denn ein API Aufruf kostet etwas. Hat man dies erledigt, dann ist es ratsam, dass man im Menü links nun unter Billing: Usage limits einstellt. 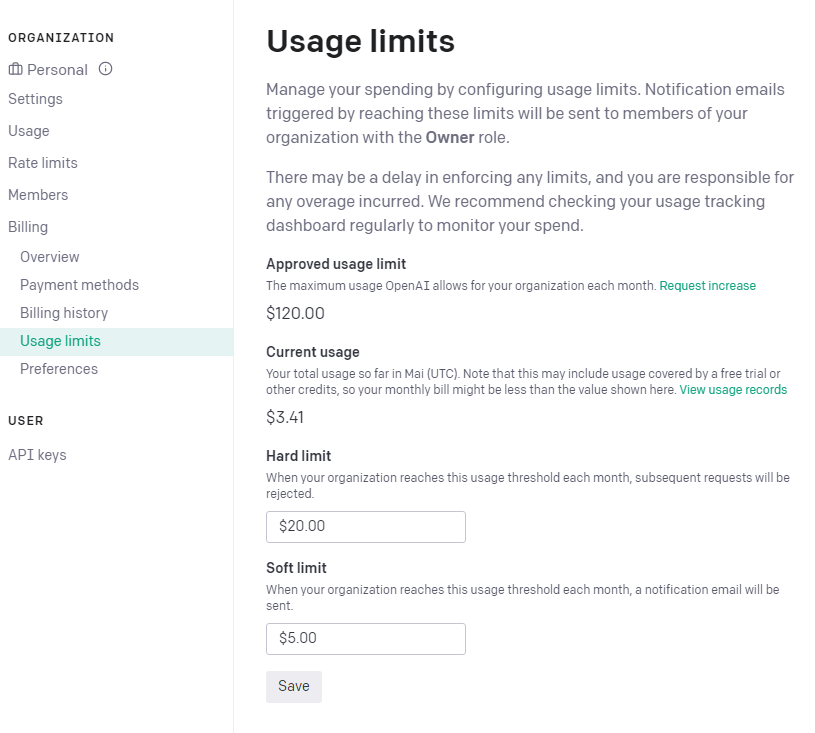
Der Verbrauch ist dann unter Usage im Menü zu sehen.
Hat man den API Key und diesen in die To Do Vo Do settings page kopiert, dann kann man die Seite Task+AI benutzen.
Anmerkung: Der API Key, wird in To Do Vo Do, wie auch die anderen Einstellungen, im Browser unverschlüsselt gespeichert. Daher sollte man den Key nicht an einen öffentlich zugänglichen Browser eintippen.
Zurück zur Tasks+AI Seite: Zunächst muss man die Daten auswählen, mit denen gearbeitet werden soll: Welche Listen und welchen Status. Die einzelnen Tasks werden aufgelistet und können angeklickt werden. Genau diese Daten werden nun beim Initialisieren von der AI an OpenAI übermittelt. Diese Daten stehen schließlich zur Verfügung, wenn man eine Frage im darunterliegenden Chat stellt.
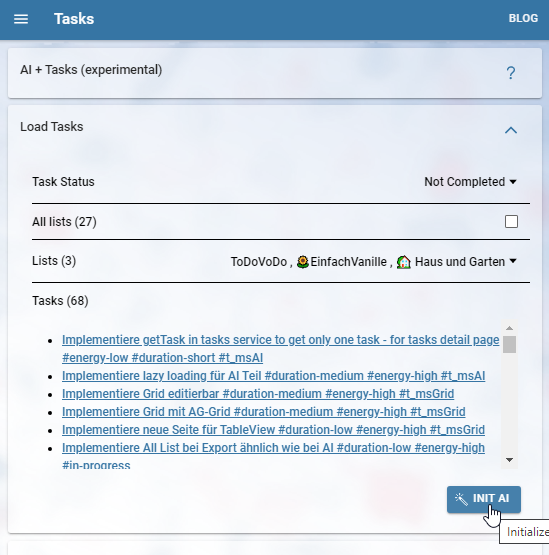
Auch der Chatverlauf wird bei einer Anfrage mitgesendet, damit die Antwort der KI auch Bezug auf die Chat History nehmen kann.
Settings
OpenAI bietet einige Modelle an, die zum Chatten geeignet sind, sogenannte chat/completions models, wie ‘gpt-3.5-turbo’ oder ‘text-davinci-003’. Die Verwendung von ‘gpt-3.5-turbo’ ist billiger als ‘text-davinci-003’ und liefert auch ganz gute Ergebnisse, aus diesem Grund habe ich dieses als Default Model eingerichtet. Man kann den Modelnamen aber in den Settings ändern. Das andere Modell hat den Vorteil, dass es Links generiert, wie man es aus Bing Chat kennt. Eine weitere Einstellung in den Settings ist die Temperature, dies ist ein Wert zwischen 0 und 1 und gibt an wieviel Zufälligkeit bei der Generierung verwendet werden soll. (Liste der verschiedenen Modelle von OpenAI).
2. Welche Daten werden an wen gesandt?
Die Task-Daten werden wie bei Export und allen anderen Funktionen von To Do Vo Do direkt bei Microsoft über das Microsoft Graph API geholt. Zum Indizieren und bei der Chat Frage werden die Task-Daten dann an OpenAI gesandt. Das OpenAI API arbeitet statisch, d.h. es gibt keine Session und es kann sich daher keine Daten zwischen den verschiedenen Chat Nachrichten merken. Trotzdem können von OpenAI die Daten für das Verbessern ihrer Modelle verwendet werden. Diese Information muss man beim Erstellen des API Keys akzeptieren (OpenAI Policies).
Das Tasks+AI Service ist wirklich nur für Testzwecke gedacht, es wird ja auch vermutlich komplett obsolet, wenn Microsoft Copilot überall ausgerollt ist. Wer Bedenken hat, die Task-Daten an OpenAI zu geben, der sollte keinen API Key in den Settings eintragen, dadurch ist nur die Seite Tasks+AI nicht nutzbar, alles andere ist davon nicht betroffen.
3. Wo liegt eigentlich das Problem?
Warum ist das denn eigentlich eine Herausforderung die Task Daten in die AI zu bringen? Könnte man nicht einfach die exportierten Daten in ChatGPT kopieren und dann die Fragen stellen? Das geht nur begrenzt, denn die Anfragelänge ist stark eingeschränkt. ChatGPT und auch alle anderen Generative AI Transformers können nur eine bestimmte Anzahl an Tokens (ein Token entspricht ungefähr einem Wort) verarbeiten, alles andere wird abgeschnitten.
Eine andere Möglichkeit wäre das LLM zu feintunen, d.h. das Modell mit seinen eigenen Daten zu erweitern. Dies ist jedoch zeitaufwendig und auch teuer. Außerdem müsste man ja für jeden Benutzer das Modell anders erweitern, denn jeder hat seine eigenen Tasks.
Immer mehr KIs bieten auch die Möglichkeit Plugins einzusetzen, damit man z.B. rechnen kann. Dazu wird von der KI die Frage so aufbereitet, dass das Plugin damit dann eine Lösung ermitteln kann. Auch diese Variante wäre eine Idee auf eigene Daten zugreifen zu lassen.
Es gibt vermutlich noch andere Ansätze, wie man das Problem löst. Es kommt auf die Rahmenbedingungen an, sind es Benutzerdaten oder eine öffentliche Dokumentation, wie viele Daten und auch was soll gefragt werden (Details oder Statistiken).
4. Dokumente indizieren lassen
In diversen Dokumenten ist beschrieben, wie man ein großes Dokument, z.B. ein Buch, durchsuchen lassen kann. Dieser Ansatz wird nun auch in To Do Vo Do verwendet. Dazu wird das Dokument in Teile zerlegt, es gibt Tokenizer Services, die einen die genaue Anzahl der Tokens ermitteln würden, doch meist wird einfach nach Wörtern getrennt und die einzelnen Dokumentteile auch noch überlappend gesplittet, d.h. dass noch 20% vom vorigen Dokumentteil mit zum aktuellen Dokumentabschnitt dazu genommen wird. To Do Vo Do splittet die Informationen aller Tasks einfach in die einzelnen Tasks auf, d.h. ein Dokumentschnipsel entspricht hier genau einem Task.
Embedding = Text => Vektor von Zahlen
Zunächst werden die Task Informationen gewichtet. Aus jedem einzelnen Task wird ein kleines Dokument erstellt (Ich mache ein JSON Objekt, das müsste nicht sein, vielleicht wäre sogar ein einfaches key-value Format besser) und dann ein OpenAI Aufruf gemacht, der mit Hilfe von sogenannten Embeddings Modellen aus der Text Information einen Vektor erzeugt, der tausende Zahlenwerte enthält. Dabei passiert ungefähr Folgendes: Der Text wird beurteilt und in vielen verschiedenen Kategorien bewertet. Ich stell mir das so vor, dass es z.B. Kategorien gibt wie Katze, gehen, Luft, kalt, usw. und der Vektor ist dann 0.01, 0.05, 0.5, 0.42, … - Dadurch weiß man, dass dieser Text interessanter ist, wenn man etwas über kalte Luft wissen will, als über Katze und gehen.
Der Text wird dabei immer in Tokens zerlegt, dies geschieht auch später wieder, wenn die Frage gestellt wird. Ein Token entspricht oft einem Wort, zumindest im Englischen stimmt das häufig. Das heißt aber nicht, dass, wenn ein Wort, bzw. Token vorkommt, dies in der oberen Einteilung gleichzusetzen ist. Denn es muss im Kontext betrachtet werden, damit man entscheiden kann ob das Wort Bank etwas mit Geld oder mit einer Sitzgelegenheit zu tun hat.
Diese Werte bekommt nun To Do Vo Do als Antwort und legt sie in eine Vektordatenbank ab. Eine Vektordatenbank muss nun schnell wieder eine Task Information finden können, wenn ein Vektor gegeben ist. Es gibt online Vektordatabanken, wie Pinecone oder auch die lokal installiert werden können (z.B. Chroma). To Do Vo Do verwendet eine die im Memory gehalten wird.
Diese Indizierung der eigenen Tasks, das Embedding, passiert nun bei der Initialisierung, also wenn man auf den Button Init AI klickt. D.h. während des Chattens kann immer wieder auf diese Datenbank zugegriffen werden. Embedding geht sehr schnell und ist sehr günstig, allerdings kann die Datenmenge ja sehr groß sein, dann macht sich das schon bemerkbar.
Prompt erzeugen
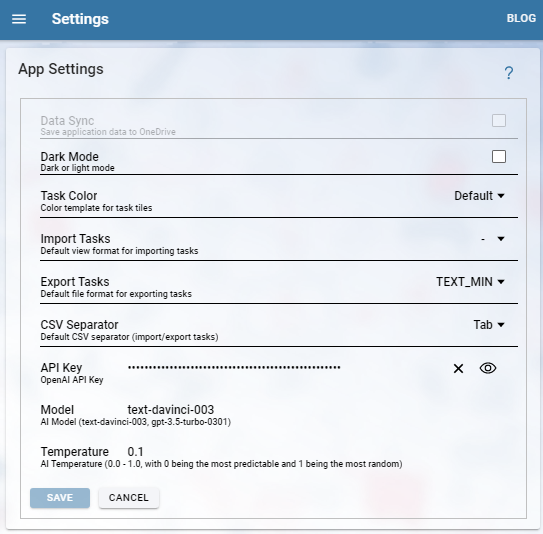
Wenn man nun eine Frage eingetippt hat und auf Submit klickt, erfolgt die Verarbeitung in zwei Abfragen:
1. Abfrage:
Zunächst wird ein Prompt zusammengestellt, der die Frage enthält und auch den bisherigen Chatverlauf. Daraus soll die KI eine neue Frage erstellen, wobei sie die Chat History und die eingetippte Frage zusammenfasst um daraus die neue Frage zu erstellen. Dieses Ergebnis, diese zusammenfassende Frage, ist dann ein Teil für den zweiten Prompt.
Wie sieht der erste Prompt nun bei To Do Vo Do aus (sowohl dieser als auch der zweite sind von der Library LangChain übernommen und nur leicht abgewandelt worden):
Given the following conversation and a follow up question,
rephrase the follow up question to be a standalone question.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:Man sieht die Platzhalter: {chat_history} und {question}.
2. Abfrage:
Nun wird diese neue Frage, also das Ergebnis der ersten Abfrage, zunächst in einen Vektor transformiert. Dies geschieht wieder mit einem Aufruf an das OpenAI Embedding Modell. Der zurückgelieferte Vektor wird nun in unserer Vektordatenbank gesucht und wir bekommen einige Treffer. Wir bekommen davon die zugehörigen Task Informationen. D.h. wir haben nun einige Tasks die gut zu unserer Frage passen.
Damit wird nun ein zweiter Prompt erstellt:
You are a helpful assistant, your name is ToVo. You are an AI assistant
providing helpful answers based on the context to provide conversational
answer without any prior knowledge. You are given the following extracted
parts of a long document of my tasks and a question. The tasks are
from my task management system Microsoft To Do. You should help to
manage my tasks. To do this, I ask a question. You should only provide
hyperlinks that reference the context below. Do NOT make up hyperlinks.
Answer in a concise or elaborate format as per the intent of the question.
Use formating ** to bold, __ to italic & ~~ to cut wherever required.
Format the answer using headings, paragraphs or points wherever applicable.
=========
{context}
=========
Question: {question}
Answer:In {context} werden die paar Task Informationen eingefügt, die wir gerade aus der Abfrage an die Vektordatenbank erhalten haben und die Frage aus dem Ergebnis der ersten Abfrage wird in {question} eingefügt.
GPT (Generative Pre-trained Transformer)
Der Transformer ist das Programm, das Service, das mit Hilfe des Models, dem LLM, die Anfragen bearbeitet. Es ist eine Generative AI, sie transformiert die Frage in eine Antwort. Es wird immer das nächste Wort (der nächste Token) ermittelt, abhängig von den bisher erzeugten Tokens und den Tokens der Frage. Außerdem ist eine gewisse Zufälligkeit dabei, dieser Parameter Temperature von oben, der eine Antwort entweder kreativer oder faktenorientierter erscheinen lässt. So ein Transformer besteht aus verschiedenen Komponenten.
Zunächst wird die Anfrage im Tokenizer in einzelne Tokens zerlegt. Damit wird dann mit Hilfe von Embedding die Anfrage in einen Vector transformiert. Somit hat man eine semantische Repräsentation der Anfrage (viel kalte Luft und wenig Katze und gehen - Beispiel von oben). Zusätzlich hat der Vektor auch eine Reihenfolge seiner einzelnen Werte (Positional Encoding).
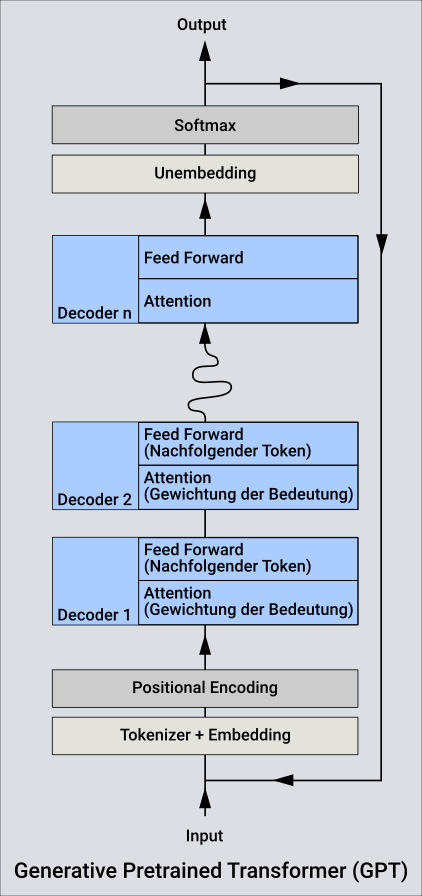
Der Transformer hat nun eine Anzahl an Decodern, die alle gleich sind. Sie sind mit unterschiedlichen Parametern konfiguriert (sie sind speziell trainiert). Der erste Decoder bekommt nun diesen Vektor aus dem Embedding als Input und erzeugt daraus wieder einen Vektor. Und das ist dann der Input für den zweiten Decoder. Ein Decoder gewichtet seinen Input und dann wird noch eine Vorhersage über die Wahrscheinlichkeit für das nachfolgende Token ermittelt (nennt sich Feed Forward). Die Decoder werden also nach der Reihe durchlaufen und am Ende kristallisiert sich ein neues Token heraus (ein Wort für die Antwort). Dieses wird dann zusammen mit der Anfrage und bisherigen Antwort wieder in die Decoderreihe gesteckt, um das nächste Wort zu ermitteln. Eigentlich kommt beim letzten Decoder wie auch bei jedem anderen ein Vektor raus. Das Wort wird durch unembedding ermittelt und dann entweder das mit dem höchsten Wahrscheinlichkeit oder je nach Kreativitätslevel (Temperature), das ein wenig abweicht, ausgewählt.
LLM
Das Large Language Model (LLM) ist nun die Basis mit der gearbeitet wird. Diese LLMs werden mit irrsinnig vielen Texten gefüttert (Pretraining - versucht selbst das nächste Wort zu erraten und vergleicht das mit dem richtigen Wort) und je nach Modell auch noch mit Feintuning angepasst, indem Fragen und Antworten zur Verfügung gestellt werden.
Je nach Modell kann eine maximale Anzahl an Token verwendet werden, um die Antwort zu generieren. Bei GPT 3.5 sind das z.B. 4096 Tokens. In dieser Menge muss nicht nur die Antwort Platz haben, sondern auch die Frage. Und das ist auch der Grund, warum man mit dem erklärten Prozess die interessante Information zuerst vorfiltert und nur diese dann in die Frage verpackt. Wie weiter oben schon erwähnt, kann man mit dieser Methodik lange Dokumente, ganze Dokumentenbibliotheken oder eben die Tasks von Microsoft To Do als Context für die Fragen zur Verfügung stellen. Als Parameter bei einer Anfrage an OpenAI API wird immer auch eine maximale Anzahl von Tokens mitgegeben, die er verwenden soll. (Aktuell gebe ich bei To Do Vo Do max_tokens=2000 mit.)
Tool/Library
Da ich die Library LangChain verwende (gibt es für Python oder für JavaScript), muss ich mich eigentlich um den genauen Ablauf nicht kümmern, genau das übernimmt die Bibliothek. Doch es erleichtert es ungemein, wenn man die Prozesse kennt, die da ablaufen, weil man dadurch ein Verständnis bekommt, wo Optimierungen stattfinden können. Außerdem gibt es natürlich verschiedene Prozesse und man muss entscheiden, welcher für die eigene Aufgabe passt (Question Answering, Summarization, …).
5. Erkenntnisse
Token
Man kann sich die Token anzeigen lassen mit Hilfe des OpenAI Tokenizer Tools. Man sieht, dass Satzzeichen auch ein Token sind und ein Token ist oft nur ein Teil eines Wortes, z.B. bei sitzen: sit, das macht auch Sinn, denn sitzen und sitzt oder Sitzgelegenheit oder Sitz, das gehört semantisch schon zusammen.
Beispiel:
Er sitzt am Stammtisch. - 10 Token
Er, sit,z,t, am, St,amm,t,isch,.
He sits at the regulars' table. - 8 token
He, sits, at, the, regulars,', table,.Die Kosten für eine Anfrage sind immer abhängig, wie viele Token verarbeitet werden. Wobei hier nicht nur die Frage, sondern auch die Antwort mitgezählt wird. Und zur Frage gehört natürlich der gesamte Prompt, also auch die system Message, welche die KI grundsätzlich anweist (You are a helpful assistant, your name is ToVo. You are an AI assistant providing helpful answers…).
Embedding
Beim Absenden einer Frage wird zunächst dieser Satz über embedding in einen Vektor konvertiert, damit man die interessanten Einträge in der Vektordatenbank dann abfragen kann.
Beispiel dafür_ “What could I do today?” Die KI erzeugt daraus folgende Antwort: { “object”: “list”, “data”: [ { “object”: “embedding”, “index”: 0, “embedding”: [ -0.0058261855, -0.004762416, 0.0035939054, … (hier 1530 Werte entfernt) 0.00441219, 0.006068398, -0.04417427 ] } ], “model”: “text-embedding-ada-002-v2”, “usage”: { “prompt_tokens”: 6, “total_tokens”: 6 } }
Möglichkeiten eine KI zu erweitern.
Finetuning, Plugins oder wie in meinem Fall Prompts die mit Zusatzinfos angereichert werden und die Daten durch Embedding vorher in einer Vektordatenbank gespeichert werden. All das wurde bereits weiter oben angesprochen.
Statistic Daten
Meine Frage, wieviele Tasks habe ich, ergab eine falsche Antwort. Der Grund ist klar, da die KI durch den verwendeten Prozess nur einige Tasks vorgelegt bekommt zusätzlich zur Frage und zum Chatverlauf, sieht sie die Anzahl nicht. Da mich das sehr störte, habe ich folgende Änderung gemacht: Es wird zu den Task Informations Dokumenten ein zusätzliches Dokument generiert und mitgeliefert. Dieses Dokument enthält ein paar statistische Werte über die Tasks, aktuell sind das die Anzahl der Aufgaben, die Anzahl der Listen, die Namen aller Listen. Wird nun eine Frage diesbezüglich gestellt, dann liefert die Suche in der Vektordatenbank auch dieses Dokument und damit kann die KI die Frage beantworten.
Bing Chat - Edge Sidebar - Format der Task Informationen
Ich habe zunächst mit Bing Chat, bzw. eigentlich mit der Sidebar vom Edge Browser getestet, indem ich die To Do Vo Do Export Funktion verwendet habe, mir also Tasks für eine Liste auflisten ließ und dann Fragen über den Inhalt gestellt habe. Auch hier gab es Schwierigkeiten, dass die einfache Frage, wieviele Aufgaben ich in der Liste habe, falsch beantwortet wurde. Da meine Export Funktion aktuell nur die Tasks einzelner Listen ausgeben kann, war das eine Einschränkung, die ich mit Tasks+AI aufheben wollte. Ich konnte mit der Sidebar testen, ob es Nachteile gibt, wenn ich das JSON Format verwende, denn die Tokenanzahl steigt natürlich, allerdings waren die Antworten besser, da wohl die Trennung zwischen den Tasks eindeutiger ist, als mit dem Textformat. Trotzdem könnte hier noch erhebliches Verbesserungspotential enthalten sein, indem ich ein geeigneteres Format für die Task Informationen bereitstelle. JSON enthält doch sehr viele Klammern und Hochkommas, die unnötig sind. Zunächst habe ich je Task die ganze JSON Repräsentation eines Tasks als Dokument übermittelt. Dies habe ich aber vereinfacht, da viele Ids vorkommen und auch komplexe Informationen, wie die Info, wenn sich ein Task wiederholt. Wenn man schon Daten hat, die eine Struktur haben, dann ist es sicher empfehlenswert diese Daten aufzubereiten, damit unnötige Infos nicht an die KI gesandt werden.
LLM und Rechenleistung
Das Large Language Model bleibt im allgemeinen immer gleich, zumindest bis es mal wieder neu generiert wird. Das Erzeugen des Models ist sehr rechenintensiv und dadurch auch energieintensiv und teuer. Aber auch das Generieren einer Antwort ist rechenintensiv. Mein Versuch GPT4All war sehr lehrreich, denn nach über zwei Minuten intensiver Arbeit des Computers, mit 100% CPU und Memory Auslastung, kam die Antwort und der Lüfter am PC konnte wieder langsam leiser werden. GPT4All ist ChatGPT ähnlich, aber eben lokal auf seinem eigenen Rechner installierbar. Man hat verschiedene LLMs zur Verfügung, wobei eines davon bis zu 8GB groß ist. Kleiner Tipp: Wenn man das ausprobieren will, am besten das Modell im Browser und nicht mit GPT4All downloaden, der Download bricht dort immer wieder ab.
Verschiedene Modelle - Kosten
Ein wichtiger Schritt bei der Erstellung einer KI Anwendung ist die Auswahl der jeweiligen Modelle und damit auch die Kosteneffizienz. Die Modelle sind auch vom Preis sehr unterschiedlich. Eine Abfrage mit ‘gpt-3.5-turbo’ kostet $0,002 während das leistungsfähigere Modell ‘text-davinci-003’ $0,02 kostet (jeweils für 1K Tokens). Details erhält man unter OpenAI Api Pricing. Das Embedding während der Initialisierung darf dabei nicht außer Acht gelassen werden, meine Tests ergaben für meine 312 Aufgaben in Microsoft To Do, dass beim Klicken von ‘Init AI’ $0,03 verbraucht werden, obwohl von der LangChain library wohl immer das sehr günstige ‘text-embedding-ada-002’ Modell dafür verwendet wird.
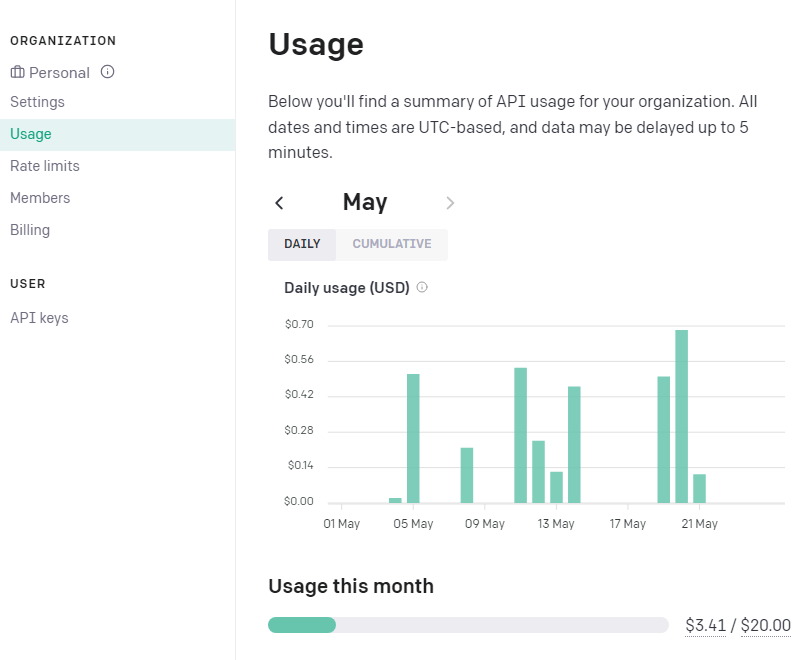
Meine Messungen ergaben:
gpt-3.5-turbo 312 Tasks - Init AI:$0.03 Chat - eine Frage: What could i do today? - weniger als $0.01
text-davinci-003 Init gleich wie vorher, da hier wohl auch das text-embedding-ada-002-v2 Modell verwendet wird. Die Chat Frage Beantwortung allerdings dauert sehr lange und schlägt mit $0.05 zu Buche.
Fragen generieren - Prompting
Extrem wichtig ist der Prompt. Kleine Änderungen bewirken, dass man das Gefühl hat, die KI versteht einen nicht. Ich hatte zunächst nur erwähnt, dass es sich um eine Liste von Aufgaben einer Aufgabenverwaltung handelt. Bei den Antworten erkannte man schnell, dass die Information fehlt, dass es meine Tasks sind, die er hier zu sehen bekommt. Dadurch kann die Antwort viel persönlicher und stimmiger ausfallen. Ein weiteres Erlebnis war, dass ich einen Antwort bekomme, ich könnte meine Tasks mit Todoist verwalten lassen. Dadurch habe ich in den Prompt noch aufgenommen, dass ich meine Tasks mit Microsoft To Do verwalte. Durch diese kleine Änderung erhält man jetzt häufig Antworten, die eine Anleitung enthalten, wie man das mit Microsoft To Do macht.
Ich habe den Prompt jetzt von LangChain übernommen und nur leicht abgeändert, aber genauso gut könnte man den Prompt selbst von einer KI generieren lassen. Dieser Ansatz wird auch häufig bei den bildgenerierenden KIs verwendet. Die KI (z.B. ChatGPT) denkt sich selbst passende Stile und Fotoeinstellungen aus und man generiert einfach unterschiedlichste Bilder zu einem Thema und sucht das passende Bild dann aus, bzw. verändert dann diesen speziellen Prompt nochmals händisch um ein besseres Bild zu generieren. Oder auch bei AutoGPT oder BabyAGI (Man nennt die auch Autonomous Agents. Ich habe keinen selbst ausprobiert.), die ganze Prozesse abbilden, indem sie einen Prompt nach dem anderen generieren, den ausführen und mit dem Ergebnis dann den nächsten erstellen und so eine komplexe Aufgabe versuchen zu lösen.
Wenn ich das richtig verstanden habe, wird auch bei der Verwendung von Plugins damit gearbeitet. ChatGPT, wenn es erkennt, es soll nun das Mathe Plugin (Wolfram) verwenden, generiert für sich einen Prompt, der ein Format für dieses Plugin erbittet. Ruft sich selbst damit auf und bekommt so die Frage, die es an das Mathe Plugin in derem Format weiterleiten kann (also z.B. ‘3*4=’). Das Ergebnis wird dann wieder in einen Prompt gesteckt, damit dann daraus eine Antwort für den Benutzer generiert werden kann.
Links und Formatierungen
Wenn man das Modell text-davinci-003 verwendet, werden auch häufig Links generiert und der Output schöner formatiert. Dazu musste eine weitere JavaScript Library dazugefügt werden, die das erhaltene Markdown Format nach Html konvertieren kann. Wenn man die Kreativität (Temperature) erhöht, dann erhält man oft Links, die ins Nirvana zeigen. Besonders interessant sind für uns natürlich die Links, die einzelne Tasks betreffen. Damit das Anklicken für diese funktioniert, musste ich zunächst die TaskId dazufügen zu den Task Informationsdokumenten. Damit dann beim Klick auf den Link auch diese Information für den Task angezeigt wird, musste eine neue Seite erzeugt werden und auch die Links in der Antwort von der KI dann dementsprechend angepasst werden.
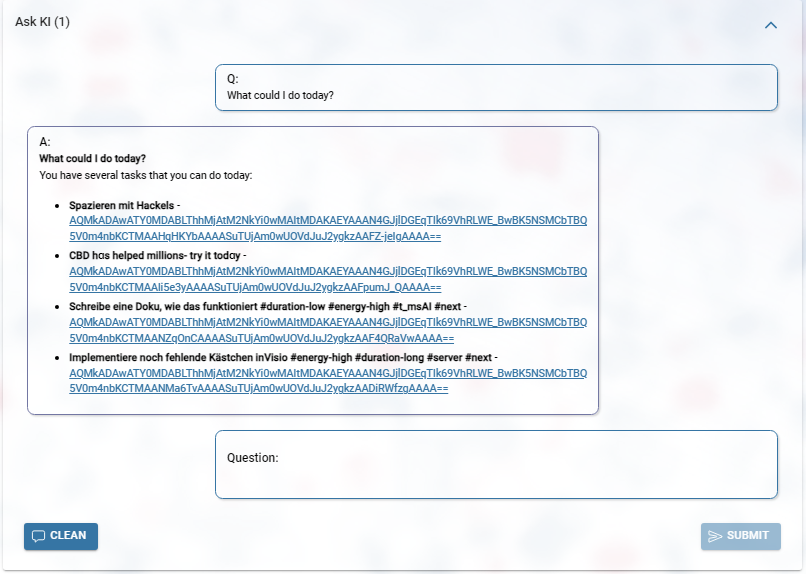
Was ist KI? Ist ChatGPT eigentlich eine künstliche Intelligenz?
Diese Frage wird gerne gestellt, wenn man erklärt, wie eine Generative AI, wie ChatGPT oder auch die Bilder generierenden KIs, wie Midjourney oder Leonardo, funktionieren. Denn sehr viel Intelligenz ist da nicht drinnen. Aber die Frage ist für Informatiker nicht so kompliziert, denn für sie ist KI einfach ein Teilgebiet der Informatik, wo Robotic und Maschine Learning usw. dazugehören. Zu Machine Learning gehören die Natural Language Processing Modelle und wenn die Text Datenmenge sehr groß ist, dann nennt man die Large Language Model (LLMs).
Sind LLMs für Aufgabenverwaltungen geeignet?
Konkrete Fragen zu einzelnen Tasks sollten gut funktionieren. Auch Fragen zu mehreren Tasks, klappen, aber wenn das sehr viele sind, dann hat die Ausfilterung vor der 2. Anfrage schon eine Entscheidung getroffen, welche Tasks die KI überhaupt sieht. Gut sollte auch funktionieren, den Chatverlauf einfließen zu lassen. Zusammenfassungen schreiben ist i.a. auch ein Schwerpunkte für LLMs, allerdings wenn es zu viele Daten gibt, dann muss man hier einen anderen Prozess anwenden und zwar wird dann das erste Teildokument zusammengefasst und dann eine Anfrage gestellt zur Zusammenfassung vom zweiten Teil, allerdings mit der Information, wie der erste Teil bereits zusammengefasst ist usw. - Diesen Prozess unterstützt nun To Do Vo Do nicht. Die allgemeinen Probleme, die LLMs immer haben, sind natürlich auch zu berücksichtigen: Oft ist die LLM ein wenig zu kreativ und erfindet Passagen oder auch Links. Auch Rechnungen kann sie nicht, schon beim Zählen von Tasks wird es schwierig, wenn sie durch unseren Prozess in der 2. Frage nur mehr eine eingeschränkte Taskanzahl zu sehen bekommt, ist klar, dass sie nicht weiß, wieviele Tasks es gibt. - Dies wurde durch den zusätzlichen Statistik Block ein wenig ausgemerzt. Manche dieser Schwächen, können in Zukunft mit Plugins ausgeglichen werden, sodass die KI dann im Internet recherchieren kann oder ein mathematisches Service befragen kann.
Datenschutz und private Daten
Ist es möglich eine KI wie sie OpenAI anbietet für seine eigenen privaten Daten, oder auch Firmendaten, zu benutzen? Das Konzept der Generativen AI ist da sehr praktisch, denn es absorbiert nicht automatisch die eingegebenen Daten. Bisher stellte man sich ja immer vor, dass die KI dann gleich alles aufsaugt und daraus lernt. Dem ist nicht so. Grundsätzlich müssen die Daten jedoch mindestens einmal übermittelt werden. Und wenn der KI Anbieter diese Daten speichert oder gar zum Training verwenden darf nach seinen AGBs, dann hat man ein Problem und wird der KI nicht vertrauliche Daten bzw. Fragen zur Verfügung stellen wollen.
Hier springen die Cloud Provider ein. Man kann z.B. das Azure OpenAI Service verwenden. Die versprechen einen, dass man die Daten nicht angreift. Will man nur mit den Daten die in Microsoft 365 enthalten sind arbeiten, so wie ich hier mit meinen Tasks, dann ist es natürlich auch sehr sicher, denn die Daten sind sowieso schon bei Microsoft gehostet.
Noch sicherer ist man, wenn man die KI bei sich hostet und ein entsprechendes LLM installiert. Die Rechenleistung ist aber auch hier, wie schon angesprochen, nicht zu unterschätzen.
Aufpassen muss man bei den spezialisierten, kleinen KI Anbietern. Da gibt es angeblich welche, da verliert man die Rechte an Dokumenten, die man hochlädt. Lädt man also ein Foto hoch, dass daraus ein lustiges Bild generieren soll, hat man der Firma das Bild geschenkt. Würde man dieses hochgeladene Foto noch wo anders benutzen, könnte diese Firma klagen, weil es ihr Bild ist. :-)
Warum nicht Azure OpenAI Service verwendet?
Ich habe deshalb nicht das Azure OpenAI Service verwendet, weil ich möchte, dass es jeder für sich ausprobieren kann. Und da fast jeder einen OpenAI Account hat, zumindest alle, die ChatGPT bereits ausprobiert haben, ist die Einstiegshürde hier viel kleiner. Die Schnittstelle ist aber, soweit ich das gelesen habe, kompatibel und auch die Library LangChain unterstützt Azure OpenAI Service.
Was ist Hugging Face
Hugging Face ist schwer zu beschreiben, denn die sind alles. Sie bieten Modelle an, man kann Modelle bei denen generieren lassen, z.B. wenn man für seine Supportabteilung einen Chatbot anbieten will. Man kann Modelle dort mit anderen teilen. Sie bieten auch eine transformer Library an, wenn man einen Transformer bauen will. Vielleicht sind sie zu sehr im Hintergrund oder ihnen fehlt noch das Teil das sie berühmt macht, oder es läuft eh alles auf Hugging Face. Auf jeden Fall stolpert man immer wieder mal über diese interessante Firma.
6. Fazit
Der Versuch mit den Tasks zu chatten ist gelungen. Leider habe ich keine wirklich sinnvollen Fragen gefunden, somit ist der Sinn von To Do Vo Do Tasks+AI stark zu hinterfragen. Ich denke, dass es Mehrwert bringen kann, wenn die Information nicht nur auf die Tasks beschränkt ist. Wenn, so wie angekündigt, Microsoft den Copilot für Microsoft 365 zur Verfügung stellt und man dann mit den Dokumenten, E-Mails, Kalendereinträgen chatten kann, wird das mehr bringen. Allerdings braucht man dann To Do Vo Do Tasks+AI nicht mehr.
Aus diesen Gründen wird To Do Vo Do Tasks+AI wohl ein experimentelles Feature bleiben. Mir persönlich hat es Erfahrung gebracht und die wollte ich mit diesem Artikel auch teilen. Auch wenn ich noch immer nicht ganz durchblicke, wie das alles funktioniert, mir ist jetzt klarer, warum manche Antworten von ChatGPT oder Bing Chat so sind, wie sie sind. Die Beschränkungen, der Ressourcenverbrauch, die Promptgenerierung, all das ist verständlicher geworden. Und die Faszination, dass da Antworten kommen, die auch von einem Menschen stammen könnten, die lässt nicht nach. - Eine interessante Zeit …
Call to action
Wie findest Du die neue Funktion Tasks + AI von To Do Vo Do? Bitte schreib mir einen Kommentar und zwar unter den entsprechendem YouTube Video. Vielen Dank für Dein Feedback.
Die YouTube Video Sammlung zu To Do Vo Do findest Du unter:


Links
- YouTube Videos zu diesem Blog Eintrag:
- To Do Vo Do Blog Eintrag: Tasks + AI in To Do Vo Do
- Microsoft To Do
- To Do Vo Do
- OpenAI
- ChatGPT
- Microsoft 365 Copilot
- LangChain JS
- Azure OpenAI Service
- GPT4All
- KI Bild Generatoren:
- Autonome KI-Agenten:
- Hugging Face